On average, everyone in Europe consumes about 125 kilograms* of paper each year, 26%* of which is used for writing.
Business paper usage is still increasing by 22%* annually. Considering the cost, both environmental and monetary, we can easily see why companies are trying to leave paper behind.
Though, there is another aspect of going digital: the process perspective. What we mean by that is that most companies strive to eradicate those time-consuming manual processes: like a simple manual invoicing process.
As long as the various business processes involve several different documents (contracts, invoices, letters, etc.), one of the key success factors of robotic automation is how we can extract and understand the information they contain.
But what makes it challenging to work with documents?
When it comes to the complexity, we can say that there are 3 types of documents:
1. Structured document has a fixed form, we know exactly where everything should go.
2. Semi-structured document isn’t as fixed as the previous one, but we know what data should be on it. Invoice is a good example for this – as we know the amount, billing date, billing address should be on the document somewhere.
3. Non-structured documents are free text in general as e-mail, contract etc.
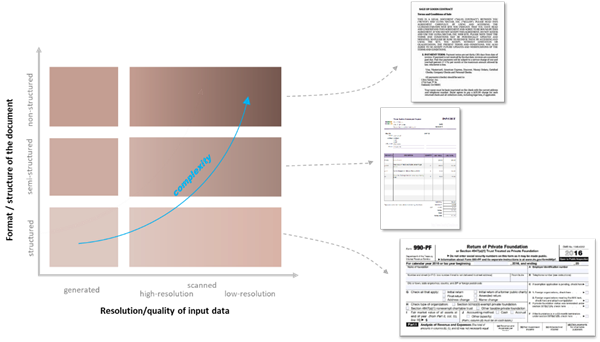
So the complexity of the structure determines how difficult it is to extract the data, but what is affected by quality and resolution?
Once we have the document on the computer the other aspect is the “digital” quality, in this sense:
- The document may be generated when no printer and no scanner is involved.
- The document may be scanned, then it is more challenging to extract data, since it is highly dependent on the quality of the scan.
Now that we know how documents look. How does the process of document handling work?
1. The very first step is to determine what the software robot should look for.
2. Then the input needs to be digitized to get its content (if it was scanned).
3. Documents must be categorized before the information can be read.
4. Then it is time to extract the information we need to get the job done.
5. Once we have done all these steps the final one is the utilisation.
As we can see, there is a general methodology that helps us to find out in which cases what technology and approach we need to apply in order to achieve our goals.
Every customer and every document management challenge is different, but that’s the basis of how BCA handles it with UiPath.
Are you thinking on automatizing your document management processes or are you just more interested in the topic?
Click on the below button to gain access to our case-study presentation!
*Sources:
The State of the Global Paper Industry (2018) – Environmental Paper Network
Facts About Paper: How Paper Affects the Environment (2019) – Toner Buzz.